-
Attentive Statistics Pooling for Deep Speaker EmbeddingAI 모델 2021. 1. 11. 16:39
Overview
- Speaker recognition should be able to get embedding that has
- Small intra-speaker and
- Large inter-speaker distance
- Evaluate most popular loss functions for speaker recognition on the VoxCeleb dataset
- Propose new metric learning objective function
Higher-order pooling with attention
- Statistics pooling
- Calculate mean vector [1]
- Calculate standared deviation vector over frame-level features h_t(t=1,...,T) [2]
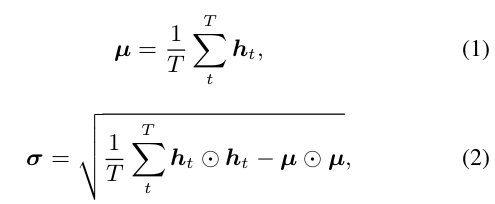
'AI 모델' 카테고리의 다른 글
- Speaker recognition should be able to get embedding that has